Installation¶
The processing part of LImA is a header only library and depends on two libraries:
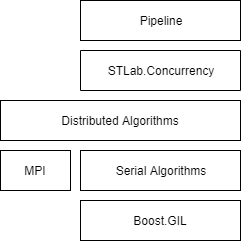
Boost.GIL that provides a solid foundation for image processing
Intel TBB that allows to easily express pipelining, task parallelism and data parallelism
Usage¶
CLI¶
To test and develop pipelines, a simple command line interface is provided:
process -p pipeline.json <image>
where pipeline.json is the pipeline definition:
{
"processes": [{
"id": 0,
"type": "flipped_left_right"
}, {
"id": 1,
"type": "save_image_tiff",
"path": "output.tiff"
}],
"connections": [{
"src": 0,
"dst": 1
}]
}
Library¶
This short tutorial should get you started with the processing library of Lima2. First some includes are required:
#include <lima/processing/pipeline.hpp>
#include <lima/processing/nodes/gil.hpp>
#include <lima/processing/nodes/io.hpp>
#include <lima/utils/factory.hpp>
Before building a pipeline, a dynamic factory of Nodes must be constructed. In the following example, two processes for flipping and saving are registered:
// Register a couple of process factories
lima::factory<any_function_process_t> fab;
fab.reg("flipped_left_right"s, [](const pt::ptree&) { return lima::processing::flipped_left_right_task{}; });
fab.reg("save_image_tiff"s, [](const pt::ptree& ptree) { return lima::processing::save_image_tiff_task{ptree.get<std::string>("path")}; });
Then, the description of the pipeline is loaded (here from file) and a channel (a pair of a sender and a receiver) is created and the processes are attached to the channel:
// Parse a JSON file into the property tree.
pt::ptree tree;
pt::read_json(pipeline_path, tree);
// Create the internal graph representation of the pipeline
lima::processing::pipeline<lima::any_image_view_t> pipeline;
pipeline.from_ptree(tree);
// Init the pipeline using the process registered with the fab
pipeline.init(fab);
Finally we can load an image and send it through the pipeline:
// Load the source image
lima::any_image_t input_image;
gil::tiff_read_image(image_path, input_image);
// Process an image
pipeline.send(gil::view(input_image));
Images¶
TODO.
Algorithms¶
Serial Algorithms¶
#include <lima/processing/serial.hpp>
Most algorithms are provided by the underlying Boost.GIL library, such as rotation, flip, subsampling, cropping (ROI) that are recalled here for the sake of completeness. The return type is a model of the ImageView concept and is omitted for clarity.
// flipped upside-down, left-to-right, transposed view
template <typename View>
auto flipped_up_down_view(const View& src);
template <typename View>
auto flipped_left_right_view(const View& src);
template <typename View>
auto transposed_view(const View& src);
// rotations
template <typename View>
auto rotated180_view(const View& src);
template <typename View>
auto rotated90cw_view(const View& src);
template <typename View>
auto rotated90ccw_view(const View& src);
// view of an axis-aligned rectangular area within an image
template <typename View>
View subimage_view(const View& src, const View::point_t& top_left, const View::point_t& dimensions);
// subsampled view (skipping pixels in X and Y)
template <typename View>
auto subsampled_view(const View& src, const View::point_t& step);
template <typename View, typename P>
auto color_converted_view(const View& src);
More Synchrotron specific algorithms are introduced as well
template <typename SrcView>
counters_result counters(const SrcView& src);
template <typename SrcView>
histogram_result histogram(const SrcView& src);
All these algorithms have their dynamic runtime versions and can be invoked with any_image_view<>:
template <typename SrcViews>
histogram_result histogram(const any_image_view<SrcViews>& src);
Distributed Algorithms¶
#include <lima/processing/mpi.hpp>
Distributed algorithms have the same function definitions.
template <typename SrcViews>
histogram_result histogram(const any_image_view<SrcViews>& src);
GPU Algorithms¶
TBD.
Combining Algorithms¶
TODO.
Most of the algorithms operate on pixels. They are applied sequentially in the pipeline.
Rather than looping over every pixels multiple times, the operations could combined and applied in one pass:
gil::for_each_pixel(src, hana::make_tuple(
lima::backsub_t(background),
lima::flatfield_t(flatfield)
lima::counters_t(counters)
));
This option is expected to be an order of magnitude faster. Obviously the order of the operations matters.
Nodes¶
Saving Nodes¶
Common functionalities of the saving nodes (such as file rotation) are factorized out in the save_image_node a base class for every saving node implementations.
Pipeline¶
Pipelining is a common parallel pattern that mimics a traditional manufacturing assembly line. Data flows through a series of pipeline tasks and each task processes the data in some way.
Synopsis¶
// T is the type of the source (sender)
template <typename T>
class pipeline
{
// Deserialize the graph
void from_ptree(boost::property_tree::ptree const& tree);
// Given a factory of tasks, init the channel
template <typename Factory>
void init_channel(Factory const& fab)
};
Implementations¶
See Intel Thread Building Blocks and associated articles Working on the Assembly Line and Parallelizing Data Flow and Dependence Graphs.
Task Metadata¶
It is important to keep track of the different transformations applied to the original image.
Metadata are modeled as simple key value pairs stored in an std::unordered_map and passed along the image to the task.
Pipeline Configuration¶
The user can specify the graph of task. Maybe some presets should be available as well.
Pipeline Generation¶
The LImA pipeline is generated according to the effective acquisition configuration (the camera configuration) and the user configuration.
Some tasks (ROI, binning) may be inserted to supplement the processing done by the hardware.
// Create a pipeline according to 'effective' acquisition configuration and the user configuration
auto p = pipeline(effective_config, user_config);
// Run the pipeline on an image
p(input_image, output_image);